lstm来做mnist的分类
之前一直对recurrent neural network不了解,所以最近研究pytorch的文档,试着自己用rnn来做mnist的分类,代码如下
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
import datetime
# %%
trainset = torchvision.datasets.MNIST('./mnist_data',download=True,train=True)
testset = torchvision.datasets.MNIST('./mnist_data',download=True,train=False)
# %%
device = 'cuda:0'
def trans(data):
ims = [np.array(i[0]) for i in data]
ims = np.stack(ims)
ims = ims/255
labels = np.array([i[1] for i in data])
ims = torch.from_numpy(ims).float()
labels = torch.from_numpy(labels).long()
return ims.to(device),labels.to(device)
# %%
trainloader = torch.utils.data.DataLoader(trainset, batch_size=500,
shuffle=True,collate_fn=trans)
testloader = torch.utils.data.DataLoader(testset, batch_size=500,
shuffle=False,collate_fn=trans)
# %%
class RNNModel(nn.Module):
def __init__(self):
super(RNNModel,self).__init__()
self.rnn = nn.LSTM(input_size=28,hidden_size=400,num_layers=1,batch_first=True,bidirectional=False)
self.linear = nn.Linear(in_features=400,out_features=10)
def forward(self,input):
#inputshape : N*28*28
input = input.permute(0,2,1)
o,(h,c) = self.rnn(input)
#print('o:',o.shape)
#print('h:',h.shape)
#print('c:',c.shape)
output = torch.flatten(h.permute(1,0,2),1,2)
output = self.linear(output)
output = F.relu(output)
return output
# %%
model = RNNModel().to(device)
for x,y in trainloader:
plt.imshow(x[0].cpu().numpy())
o = model(x)
print(o.shape)
break
# %%
model = RNNModel().to(device)
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.CrossEntropyLoss()
epoch = 30
writer = SummaryWriter('./runs/rnn_mnist '+str(datetime.datetime.now()).replace(':','_'))
for epoch_idx in range(epoch):
for index,(x,y) in enumerate(trainloader):
output = model(x)
loss = criterion(output,y)
model.zero_grad()
loss.backward()
optimizer.step()
writer.add_scalar('train/loss',loss.item(),epoch_idx*len(trainloader)+index)
with torch.no_grad():
correct_cnt = 0
test_mean_loss = 0
for index,(x,y) in enumerate(testloader):
output = model(x)
loss = criterion(output,y)
correct_cnt += torch.sum(torch.argmax(output,dim=1)==y).item()
writer.add_scalar('test/loss',loss.item(),epoch_idx*len(testloader)+index)
test_mean_loss += loss.item()
writer.add_scalar('test/loss_per_epoch',test_mean_loss/len(testloader),epoch_idx)
writer.add_scalar('test/acc',correct_cnt/len(testloader)/testloader.batch_size,epoch_idx)
# %%跑的时候用的就是如上的参数,相同的参数跑了四回,结果如下
train loss:
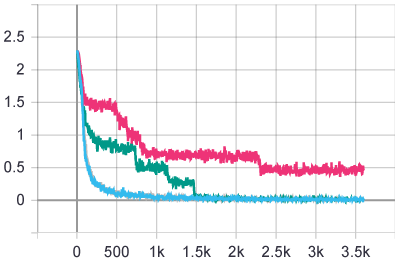
test loss:
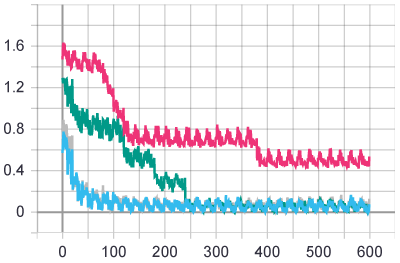
test loss per epoch:
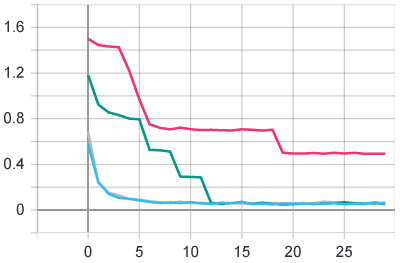
test acc:
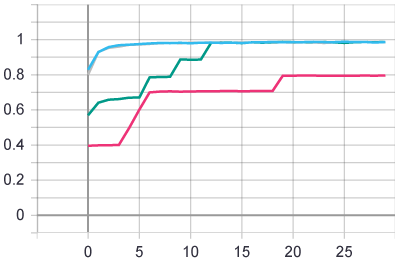
同样的参数,运行四回,其中三回都可以达到98.5%以上的准确率,但是有一回准确率停留在了80%,可能继续训练更多个epoch能让它也同样到98.5%以上吧。同样的参数和epoch数,训练结果有差异,说明还是有一定的随机性的。